![[논문 분석] EAST: An Efficient and Accurate Scene Text Detector](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdZl7O9%2FbtrtMKBjSOb%2FAAAAAAAAAAAAAAAAAAAAACCLungXx3OyxMOH1irvWNWslBGE9bhWKcIEO2B6BVeR%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1756652399%26allow_ip%3D%26allow_referer%3D%26signature%3DFCj9x2yzF0wy42jxdcR0B5I3tEY%253D)
들어가기에 앞서, 기존의 텍스트 디텍션(이미지에서 글자가 위치한 ‘영역’을 탐지하는 Detection)을 살펴본다.
Basic of Scene text detection
· 기본적 텍스트 디텍션의 목표는 글자가 위치한 bounding box 좌표를 최대한 정확히 맞추려는 것
· 그렇기에, Regression 문제로 접근한다.

· 글자 영역은 Region proposal 또는 Region of Interest(ROI)라 한다.
(좌표값 예측 방법론)
· 글자 영역의 좌표값 예측은 여러가지 방법론이 존재한다.
· 베이직한 방법론은 주로, CNN으로 이미지 특징을 추출 후, 디코더로 단어 영역을 생성하는 방식이다.
· 고전적인 Object Detection 방법 중 하나는 픽셀마다 단어 영역이 될 만한 여러 후보(Anchor box)를 만든 뒤 그 중에서 학습을 통해 ROI를 추려내는 방식으로, Scene text detection에서 사용하기도 하였다.
· 또한, 문자들이 문장등으로 붙어있을때 어디까지를 단어로 볼 것인가?의 입장에서 단어 정합성을 높이기 위해, 글자와 글자와 글자, 단어와 단어 사이 여백 등을 모두 탐지하여 정해진 rule에 따라 단어 영역으로 합치는 알고리즘도 제안되어 왔다. 그렇다면 EAST에선 무엇이 변화하였는가 ? (하단 설명)
EAST: An Efficient and Accurate Scene Text Detector(Zhou. et al., 2017)
| " 요약 " Scene Text Detection의 EAST model구조는 FCN을 변형한 구조로 각 픽셀이 단어 영역 내에 있을 확률인 score map과 각 단어 box를 추정한 후 각 픽셀과 box 4개 변 사이의 거리를 의미하는 거리정보, box가 회전된 각도 정보 등이 출력된다. 최종적으로 이를 선형결합한 형태의 loss를 활용하여 학습하게 된다. |
(Basic Concept)
· 기존 Text Detection 모델들이 3~5차례 Convolution 블록을 거치게 한 것과 달리 하나의 Convolution 블록으로 줄여 연산시간을 대폭 단축함.
· 이미지 분할을 위해 고안된 Fully Convolutional Network(FCN) 알고리즘을 활용해, 단어가 포함된 Rotated retangle 혹은 Quadrilateral box를 예측함. (회전 or 다각형 모델 등 예측)
(Basic Structure)
· Input Image DATA : input 대상 이미지(논문에서 제시된 예: 512x512 RGB image)
· Output Image DATA : Rotated rectangle bounding box의 5개 정보(x1, y1, w, h, 각도)
· U자 모양의 FCN 구조를 사용해 더욱 정확한 Localization을 하고자 함 .
· Input을 지나 이미지 박스가 인코더로 들어간다. Conv.블록의 각 채널의 수는 증가(64→384)하고 있다.
이미지는 블록을 통과하며 축소되었고 1/32로 축소된 Feature map을 생성하였다.
· 다시, 디코더 영역에서 Conv. 블록을 지나며 이미지 사이즈를 키워 첫 이미지에 가깝게 복원한다.
· 핵심은 어느 위치의 박스를 예측할 것인가? 이기 때문에, 위치 정보가 매우 중요하다 할 수 있다.
(그렇기에 U자 모양의 FCN 구조를 사용하여 앞에서 추출한 input에 가까운 Feature map들을 Concatenate하는 방식으로 글자가 있는 영역을 좀더 잘 Localization하게 사용한다. 일반적으로 이러한 형태를 U-Net이라고도 하지만, 실제 EAST 모델에서 사용하는 CNN블록은 U-Net형태와도 유사하지만 FCN형태에 좀 더 가깝다 할 수 있겠다.)
· 디코더를 거치면 최종적으로 Input Size의 1/4정도의 Score map이 생성된다. 이는 우리가 구하고자 하는 변형된 사각형(회전된, 혹은 다각형 등)에 대한 5가지 정보(x1, y1, w, h, 각도)를 구하기 유용한 정보로 구성되어 있다.
· 여기서 출력한 Score map을 취합하여 Thresholding을 지나 최종적으로 구하고자 하는 박스를 아웃풋으로 도출한다.
· 기본적 구조는 이러하며, 아래에선 핵심 알고리즘인 FCN에 대해서 더 세밀하게 알아본다.
· FCN을 설명하기에 앞서 컴퓨터 비전에서 가장 많이 다뤄지는 문제들의 큰 틀을 보자면 아래와 같다.
[컴퓨터 비전 3가지 카테고리]
- Classification (분류): 인풋에 대해서 하나의 레이블을 예측하는 작업 (AlexNet, ResNet, Xception 등의 모델)
- Localization/Detection (발견) : 물체의 레이블을 예측하면서 그 물체가 어디에 있는지 정보를 제공.
물체가 있는 곳에 네모를 그리는 등 (YOLO, R-CNN 등의 모델)
- Segmentation (분할): 모든 픽셀의 레이블을 예측 (FCN, SegNet, DeepLab 등의 모델)

· Semantic Image Segmentation의 목적은 사진에 있는 모든 픽셀을 해당하는(미리 지정된 개수의) class로 분류하는 것.
이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에 Dense Prediction이라고도 불린다.

· 주의해야하는 점은 semantic image segmentation은 같은 class의 instance 를 구별하지 않는다는 점임.
· 쉽게 말해, 상단 왼쪽 사진처럼 같은 Class에 속하는 Object(사람)가 있을 때 각각을 따로 분류하지 않고, 그 픽셀 자체가 어떤 Class에 속하는지에만 관심이 있다)

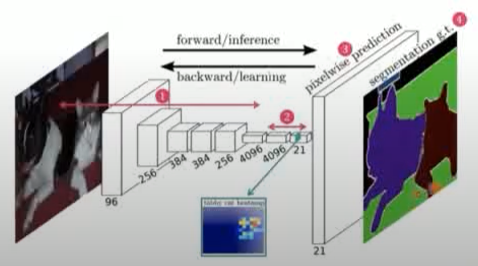
( Fully Convolutional Network(FCN) )
· 다시 FCN으로 돌아와서, 원래 FCN도 Semantic Segmentation을 위해 제안된 모델이다.
· 하지만 픽셀별로 모두 CNN을 지나게 해 구하면 연산이 비효율 적이므로 FCN은 이 문제를 해결한다.
· 문제는 기존의 CNN을 거쳐 어떤 Feature가 압축되었을 때 마지막 Fully Connected Layer를 거치게 되는데 이러면 우리가 원하는 분류에 필요한 클래스별 확률을 구하기 때문에 위치정보가 사라지게 되므로,
· Fully Connected Layer를 거치기 전까지의 Feature map(위치정보가 어느정도 보존된 Feature map)을 활용해서 이걸 다시 Transpose Convolution을 지나 Input과 비슷한 사이즈로 복원하는 것이 FCN모델 이다.
· 흔한 CNN처럼 압축할때 Conv Layer에 Pooling을 번갈아가며 사용하는데 인코더에서 압축할때와는 반대로 디코더에서 새로 복원/생성해 내야 하기에 Unpooling Transpose Convolution등을 사용한다.
( Output of EAST model )
· FCN 블록을 지나면 어느정도 처음 사이즈와 비슷하게 5개 정보(x1, y1, w, h, 각도)가 출력된 Score map으로 복원된다.
· Score map의 의미 = 이미지 사이즈에 가까운 map안의 픽셀 하나하나 마다 어떠한 값이 부여된다는 뜻이다.
· 이 값을 이용해 최종 취합하면, 우리가 원하는 박스 좌표를 구할 수 있게 된다.
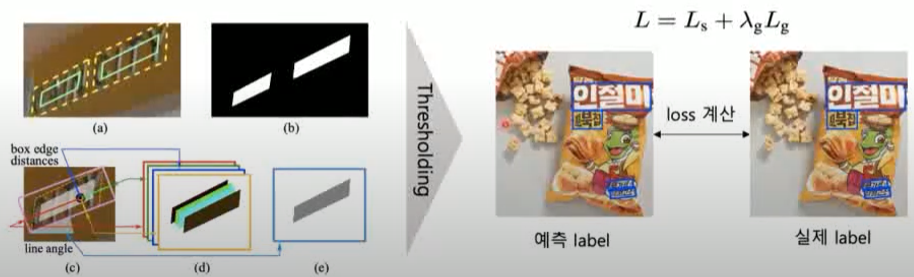
· 사진 왼쪽에서, 어떤 값을 설정해 놓았는가 하면 첫 번째 (b)에 해당되는 맵인데, 각 단어 영역을 어느정도 추정한 후 각 픽셀이 단어영역 내에 있을 확률을 0~1사이로 부과하여 높을 수록 단어가 있을 확률을 높게친다.
· 하지만, 실제로는 흐릿한 부분 등 정확하지 않을 수 있으니 (d)에 해당하는 추가 정보를 부여한다. 이는 단어박스를 추정 후 안의 픽셀을 대상으로 박스 4개 변과의 거리가 얼마인가?의 값을 각 4개 채널에 담게한다. 4개 변이기에 각 채널하나마다 값이 부여가 되고, 이 때 거리가 높게 나온다는 것은 4개의 변과 모두 거리가 멀다는 것이기에, 4가지 값이 모두 높게 나타나면 단언 영역의 중심일 확률이 높을 것이다.
· 다시, 중심인 정보를 가지고 박스가 수평기준 얼마나 회전했는지 각도 값을 저장하게 된다.
· 최종적으로 '한 가지 Score map + 다섯가지 추가정보'가 담기게 된다.
· 출력한 스코어 맵들을 취합하여 Thresholding을 지나 최종적으로 구하고자 하는 박스를 아웃풋으로 내게 된다.
· 취합하는 방법은 정보를 적절히 조합 (방법 자체는 너무 복잡하니 생략한다..)하여 어느정도 임계치를 넘을 경우 그 부분을 알맞는 박스로 추정할 수 있다고 보며 레이블을 예측하게 된다.
· 실제 레이블을 바탕으로도 아까 사용했던 Score map+5가지 정보를 생성할 수 있는데, 이를 더하여 loss 값을 낸다.
· L (최종 Loss) = Ls(스코어맵간 차이) + λg Lg(5가지정보간 손실)
(전체 손실 함수는 위와 같이 score map loss (Ls) 와 geometry loss (Lg) 로 구성된다. Lambda 는 각 손실에 대한 가중치를 조정하는 hyper-parameter 이다. )
( Experiment Result )

· Scene text detection 문제를 푸는데 굉장히 자주 사용되는 대표적인 오픈 데이터 셋은 ICDAR2015라는 데이터 셋이고 80퍼이상의 성능을 보인다.
· 요즘 대부분 좋은 모델은 90프로 정도 성능을 보이기에 해당 기준엔 못 미치지만, 이 후 Scene text detection 분야에서 END TO END모델에 EAST모델이 사용될 수 있는 지표가 되어주었다.
※ 참고 ※
· 김성범 소장님 유튜브 中 _ [DMQA Open Seminar] Scene Text Detection and Recognition
· https://github.com/chullhwan-song/Reading-Paper/issues/73
· https://kaiertech.blogspot.com/2019/09/east-efficient-and-accurate-scene-text.html
'AI' 카테고리의 다른 글
| DenseNet (0) | 2022.07.28 |
|---|---|
| 인공지능(AI)의 1차, 2차 겨울 (0) | 2022.05.10 |
| fit, transform, fit_transform (0) | 2022.02.01 |
| 활성화 함수 Activation Function (0) | 2021.12.27 |
| Gradient Vanishing(기울기 소실) 문제 간단 설명 (0) | 2021.12.26 |